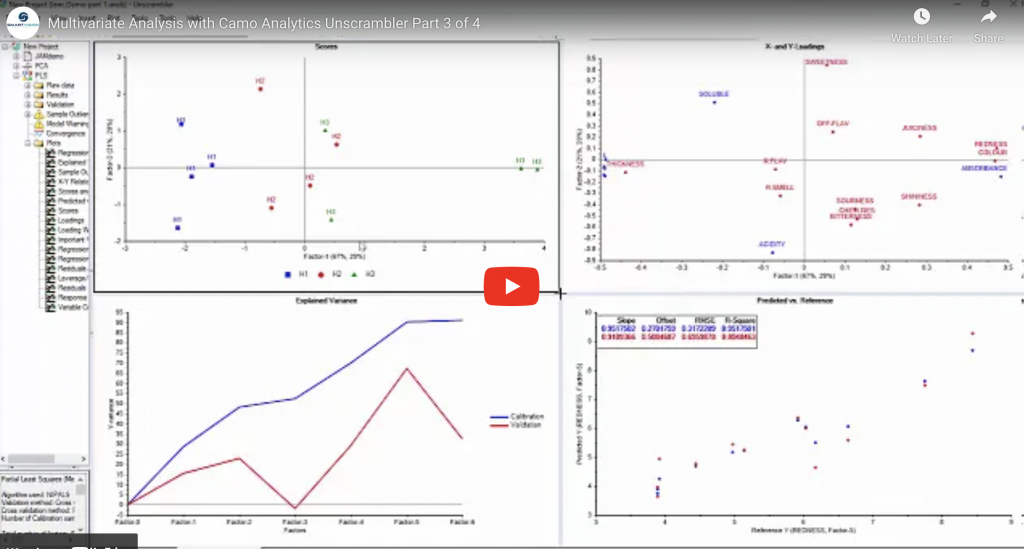
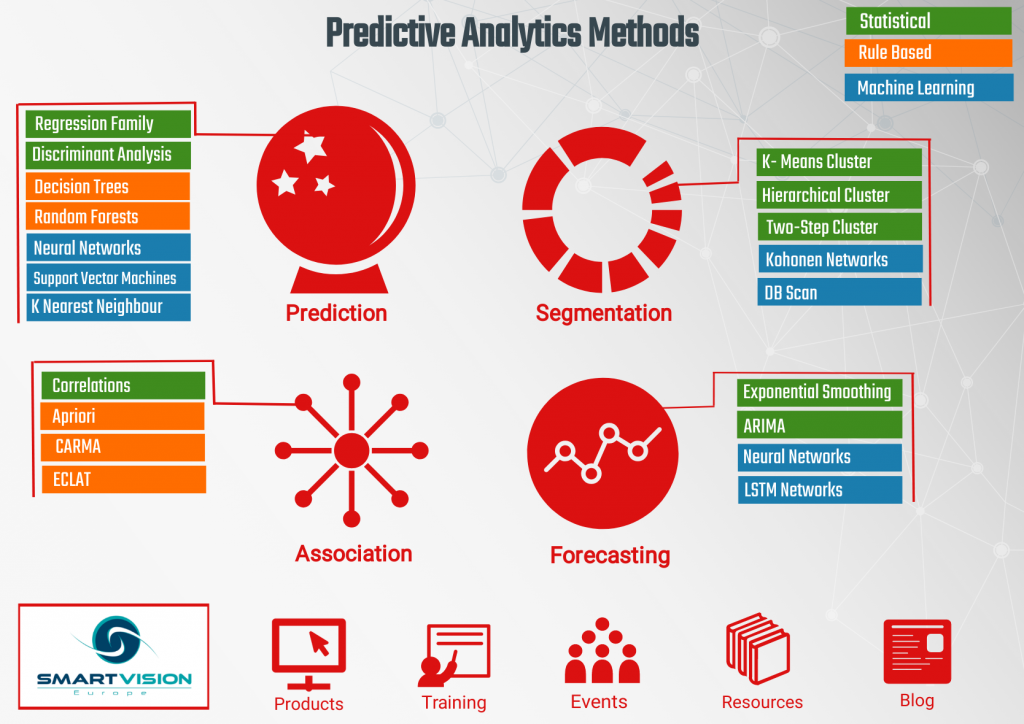
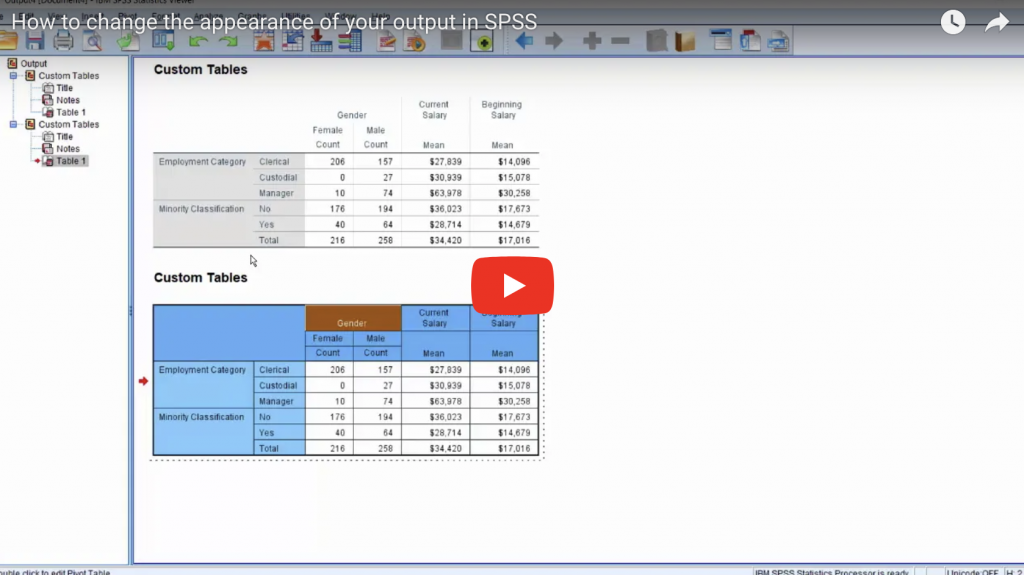
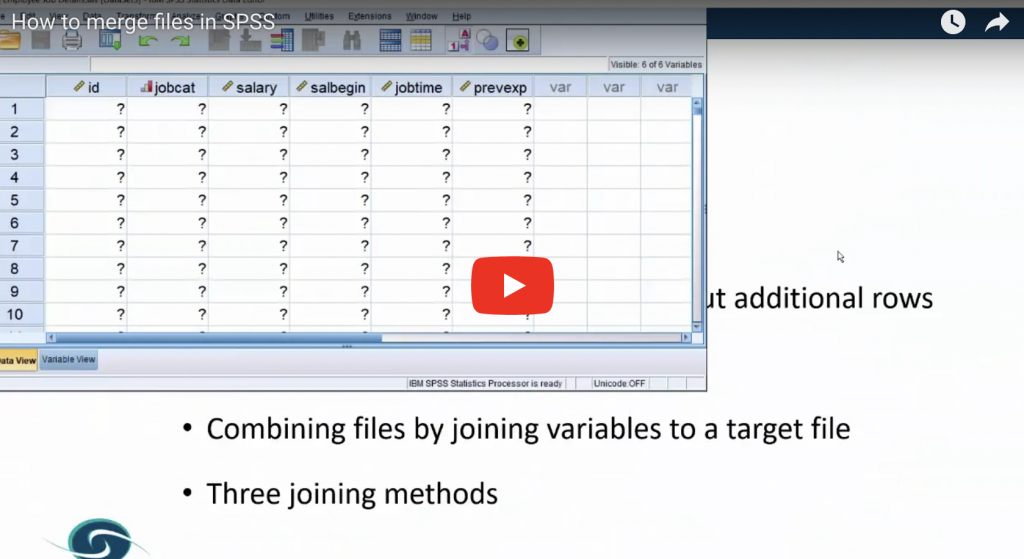
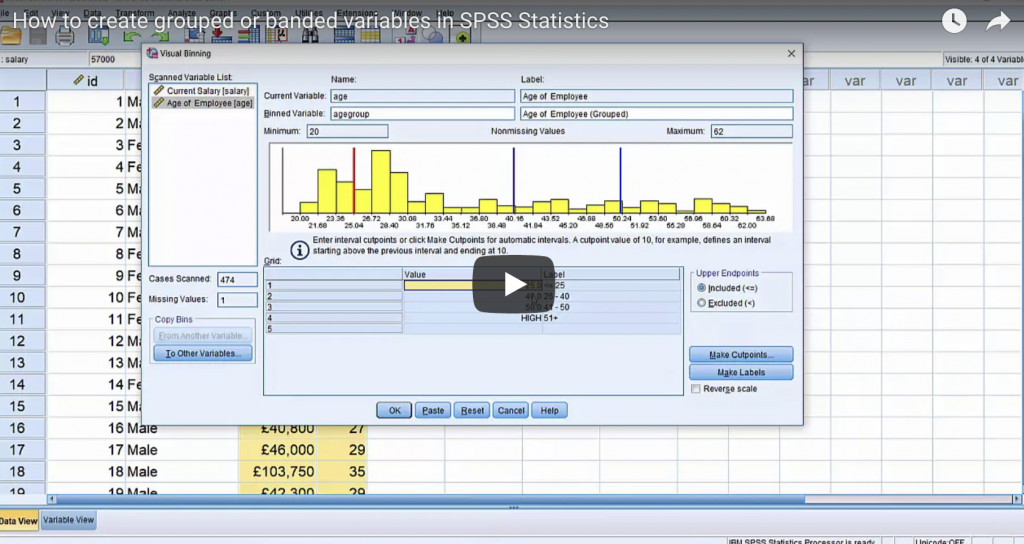
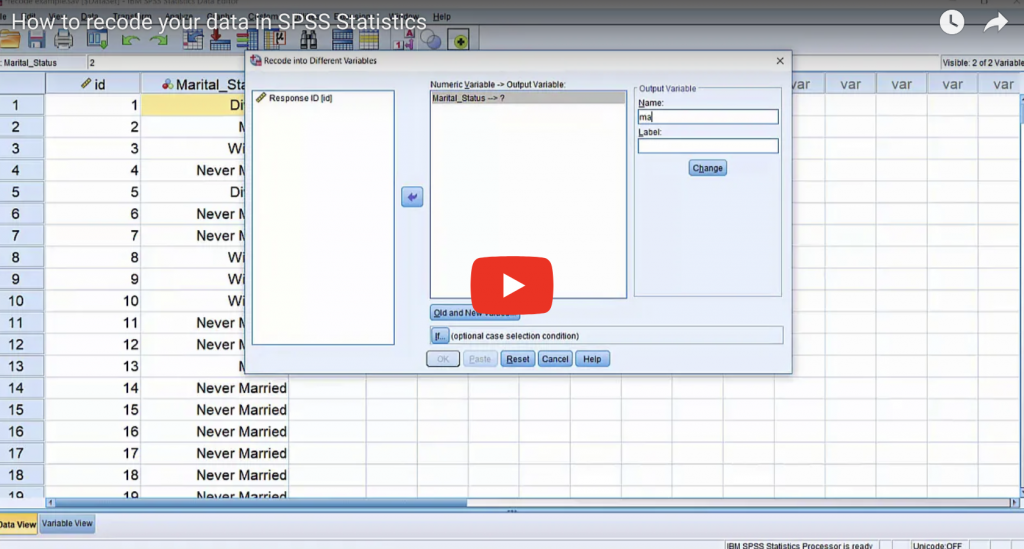
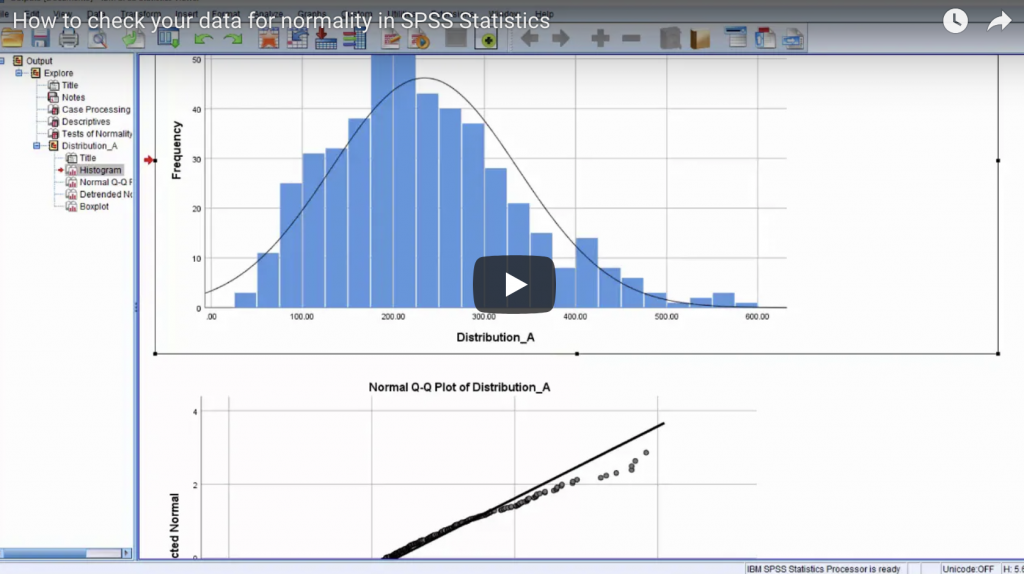
Finding normality – why is the normal distribution so important when we so rarely encounter it in real life?
This is the fourth post in our ‘eat your greens’ series – a back to basics look at some of the core concepts of statistics and analytics that, in our experience, are frequently misunderstood or misapplied. In this post we’ll look in more depth at the concept of the normal distribution. One of the first …