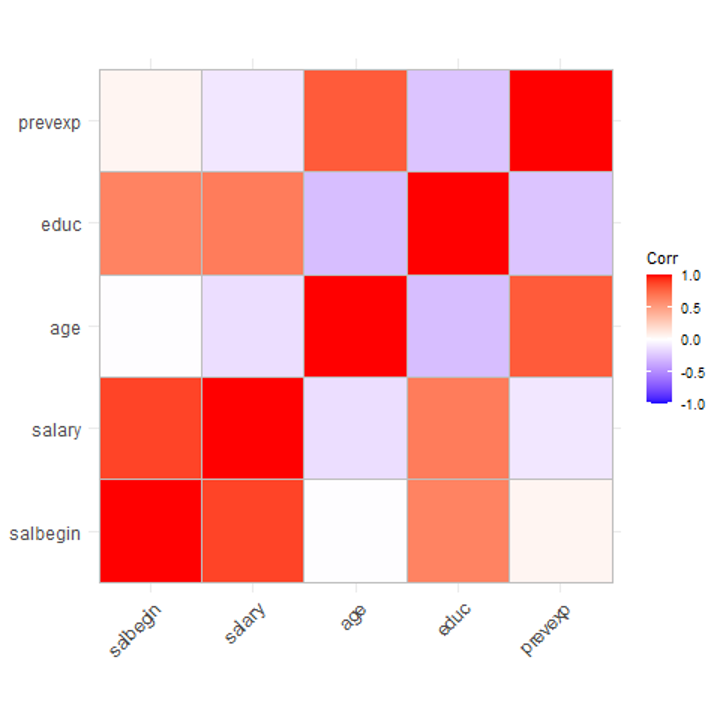
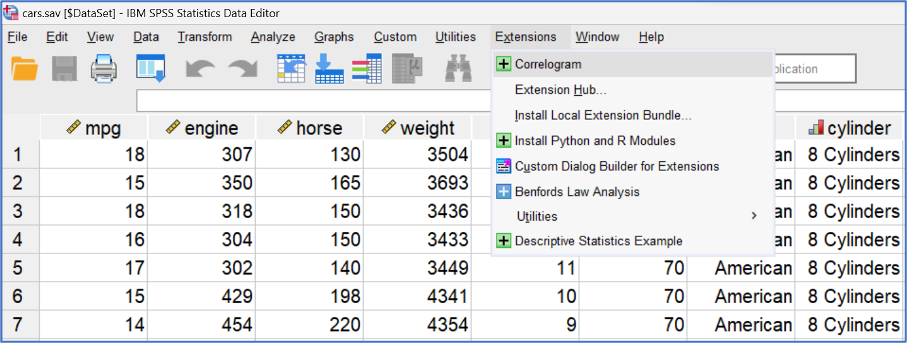
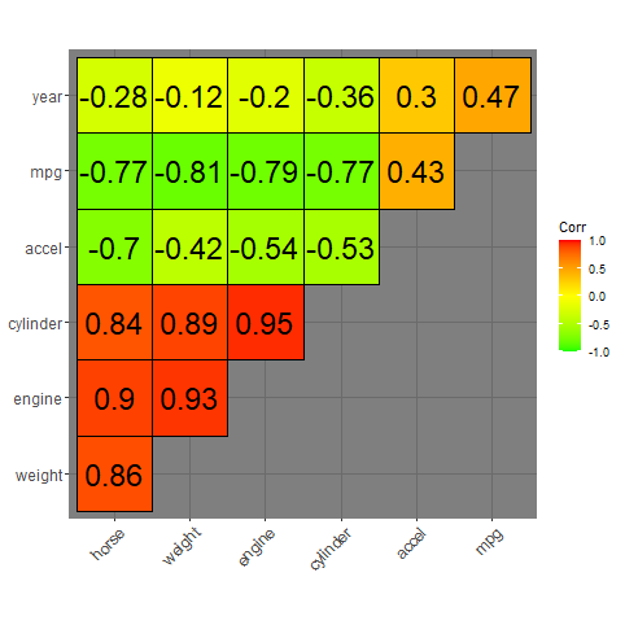
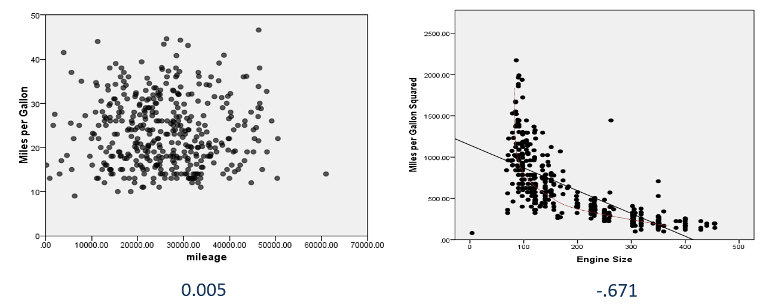
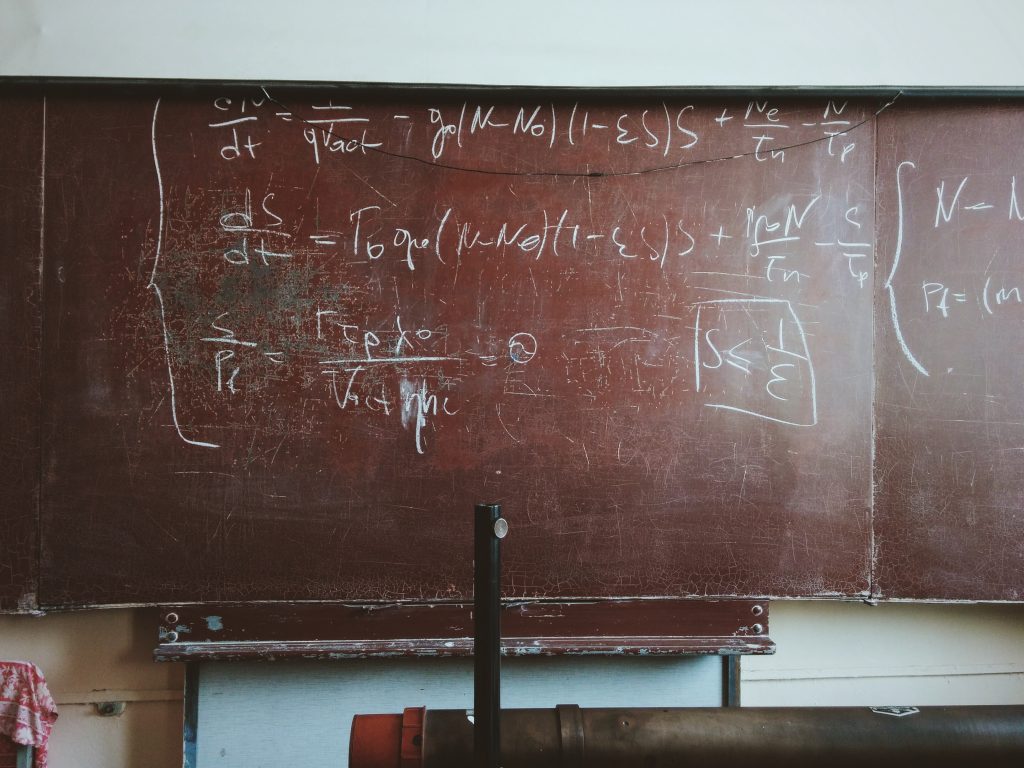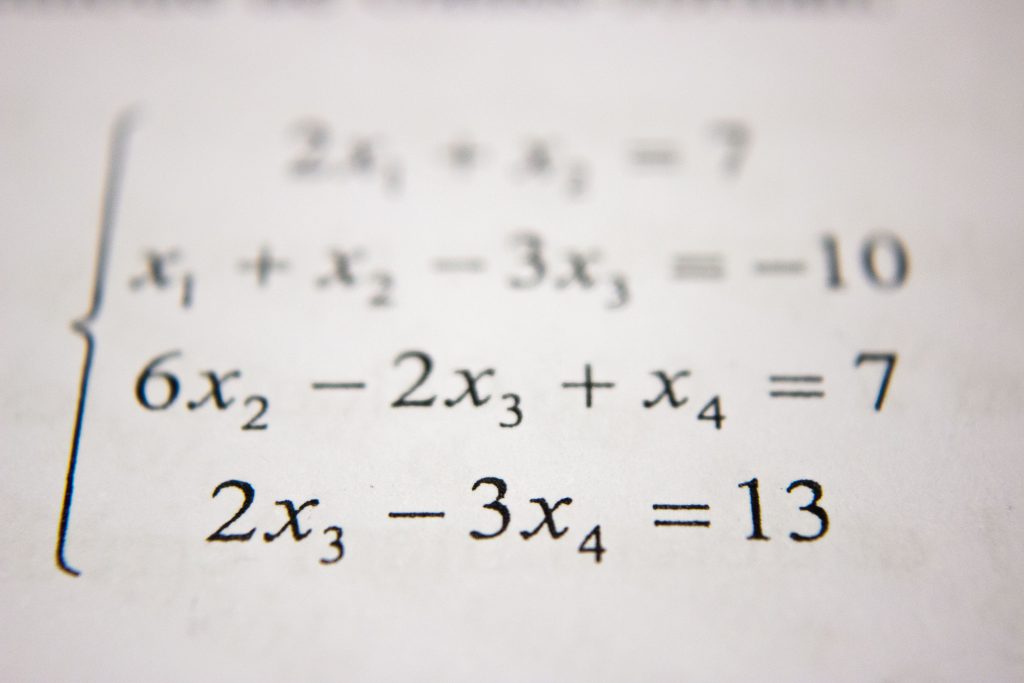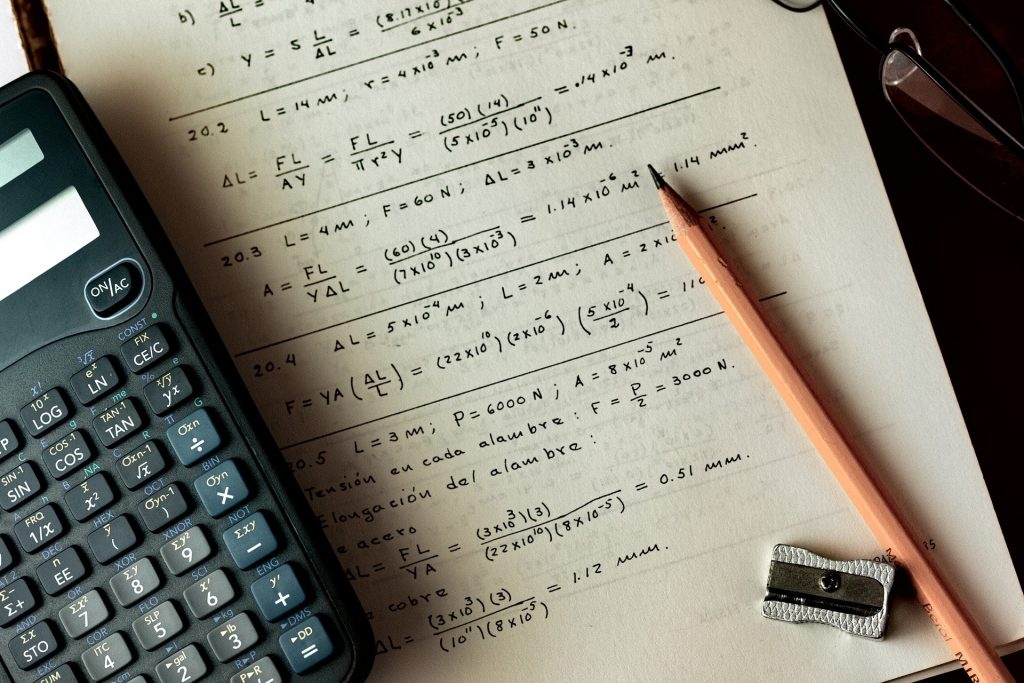What’s new in SPSS v32?
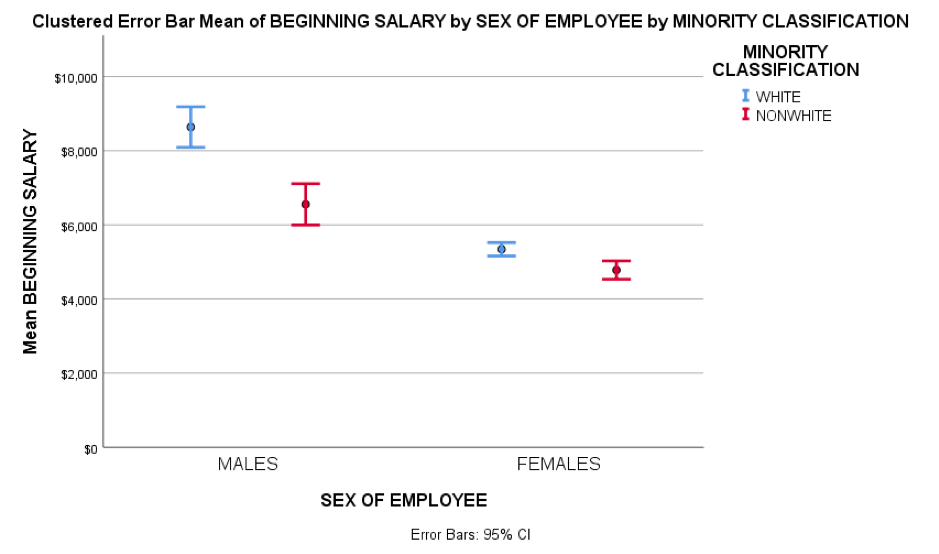
In April IBM released a new version of SPSS Statistics. The version 32 edition included new analytical procedures as well as some general usability enhancements. Read this blog to find out more.
What’s new in SPSS v32? Read More »