Cleaning and formatting data for analysis purposes is a perpetual problem for any researcher. Indeed, one of the most challenging aspects of analysing data is that often you may not spot issues with the data until you’re already well into a project. For users of SPSS Statistics, the software includes a number of procedures that are specifically designed to deal with multiple data cleaning issues. As an added bonus, pretty much everything can be recorded as syntax, so for those who need to prepare and analyse similar data extracts on a regular basis, this can all be automated.
Here are a list of some of the most common data cleaning problems that you are likely to encounter and which SPSS procedures help to resolve them. To my mind, data cleaning issues fall into two broad classes: firstly, problems with how the data has been formatted and secondly, problems with the data itself.
Data Format Problems
When importing data from third-party platforms the data are often formatted in ways that are sub-optimal for SPSS. Even something as simple as a variable name can cause headaches, as SPSS tends to be quite proscriptive regarding the inclusion of things like special characters or field names that start with a number. Users can of course rectify issues like this by manually renaming the fields within the Variable View tab of the Data Editor window, but it’s worth knowing that the syntax command RENAME VARIABLES allows you to instantly rename a list of multiple variables in one go. In a similar vein, we can also assign or change multiple labels through the VALUE LABELS and VARIABLE LABELS commands.
Often a dataset will contain special characters that indicate if a group or value should be excluded from the analysis process. Sometimes the easiest way to deal with these data points is to assign them as missing values. In SPSS, missing values can be applied to individual values and well as ranges. They may also be assigned via syntax.
Another common issue relates to date/time fields. Data from third party survey platforms as well as text files, spreadsheets, database tables occasionally export date fields in formats that SPSS may not immediately recognise as a time-based variable. Fortunately, SPSS has its own dedicated Date and Time Wizard that allows the users to create date/time variables from fields where date/time data have been encoded as strings. It also allows users to create date/time variables from variables holding parts of date or time fields.
| Data Format Problem | Solution |
| Edit multiple variables names | Use the RENAME VARIABLES syntax command |
| Edit multiple variables labels | Use the VALUE LABELS or VARIABLE LABELS syntax command |
| Ignore non-legitimate values | Use the MISSING VALUES syntax command |
| Edit the level of measurement for multiple variables | Use the VARIABLE LEVEL syntax command |
| Deal with Date/Time fields | Click Transform > Date and Time Wizard |
| Convert string variables to numeric | Click Transform > Automatic Recode |
Problems with data values
The other class of problem requiring data cleaning, relates to issues with the data values themselves. In these situations, the analyst might want to take care of extreme values, data entry errors, inconsistencies, duplicate records or illogical relationships in the file. In SPSS, one of the most valuable tools for dealing with these problems is the Validate Data procedure. This is acts as a one-stop-shop for some of the most common data quality and cleaning issues that users are likely to encounter. The Validate Data procedure creates both viewer reports and fields indicating when a record or variable fails to meet a pre-specified quality threshold. By default, the procedure will flag fields containing too many missing values, insufficient variation, too many cases in a single category, too many categories with a count of 1, incomplete IDs or cases with duplicate IDs.
It also allows users to create their own single-variable rules that check whether values fall outside an accepted range (e.g., ensuring that a sample does not contain respondents who are recorded as too young or too old). These rules can be saved and shared with other users. It even comes with a set of pre-built rules that ensure variables contain legitimate UK postcodes or US State names.
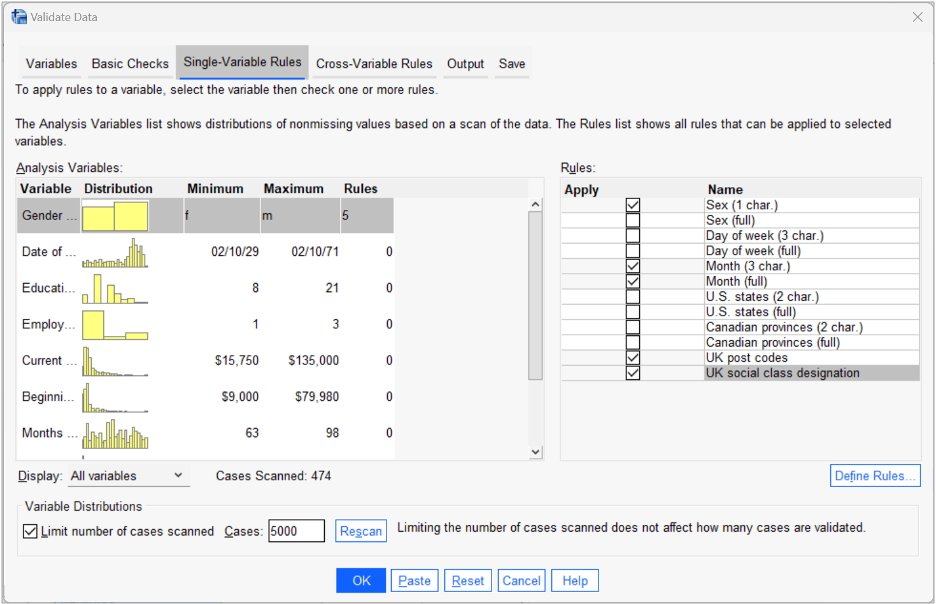
The Validate Data dialog: Single-Variable Rules tab
The procedure also allows users to define their own cross-variable rules to check that the values in a given case make logical sense and do not contradict each other (e.g., discharge date recorded as prior to admission date). On top of this, SPSS contains a portfolio of other procedures that help to address data cleaning issues such as the Recode command for creating more consistent or simpler categorisations within variables, the Identify Duplicate Cases procedure which affords even more control over what constitutes a duplicate record and how the issue should be resolved, the ability to identify unusual cases and an entire suite of tools dedicated to the analysis and imputation of missing values.
| Data Value Problem | Solution |
| Detect common data quality issues | Click Data > Validation > Validate Data |
| Define data validation rules | Click Data > Validation > Define Rules |
| Create new variable categorisations | Click Transform > Recode into Different Variables |
| Replace missing values in a series | Click Transform > Replace Missing Values |
| Identify outliers | Click Analyze > Descriptive Statistics > Explore > Statistics > Outliers |
| Identify duplicate cases | Click Data > Identify Duplicate Cases |
| Identify unusual cases | Click Data > Identify Unusual Cases |
| Analyse missing values | Click Analyze > Multiple Imputation > Analyze Patterns |
| Impute missing values | Click Analyze > Multiple Imputation > Impute Missing Data Values |