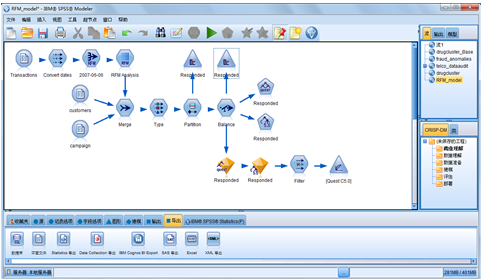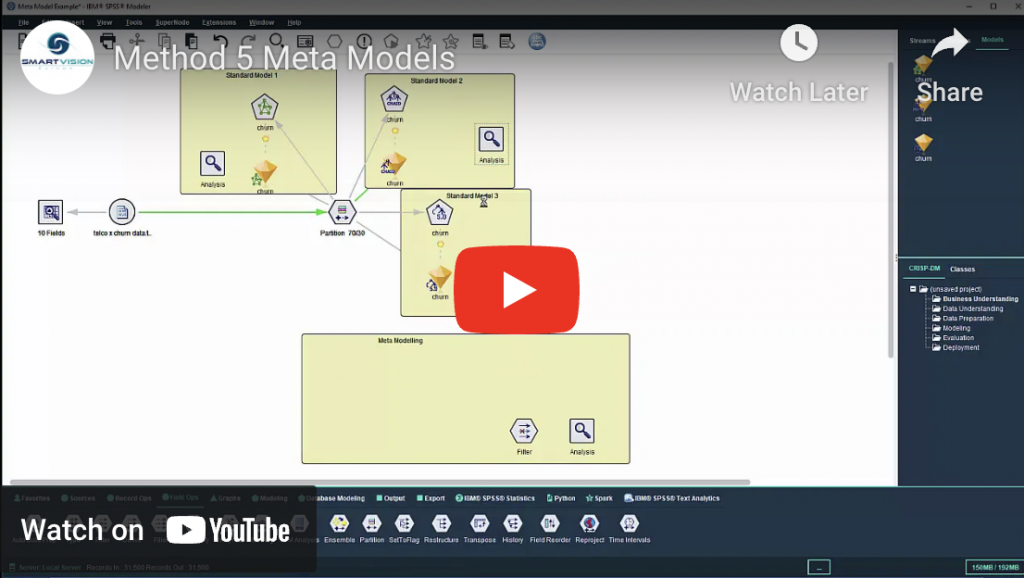
6 secrets of building better models part five: meta models
The idea of meta modelling is to build a predictive model using the predictions or scores generated by another model. By adding the predictive scores generated by an initial modelling algorithm to an existing pool of predictor fields, a second algorithm can then exploit these scores in to build a final more accurate model.
6 secrets of building better models part five: meta models Read More »