Many analysts who are interested in building predictive models invest a lot of their time and effort in trying to understand how to best tune the parameters of the specific technique that they are using, whether that technique be logistic regression or a neural network, and they are doing this in order to achieve the best accuracy of the resultant model.
In this series of videos we look at some often overlooked approaches that can be applied in the same way to a wide variety of algorithms and which may lead to better predictive accuracy. In all of our examples we’ll focus on improving the accuracy of a predictive model applied to a classification prediction problem.
Bootstrap aggregation or strapping
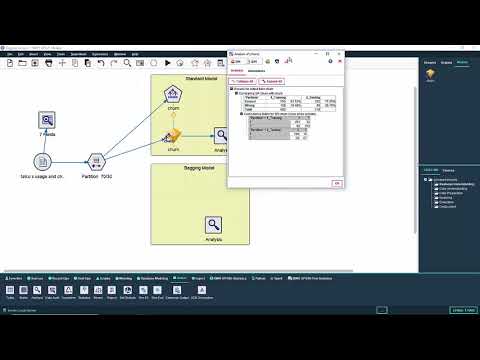
Bootstrap aggregation, also called bagging, is a random ensemble method designed to increase the stability and accuracy of models. It involves creating a series of models from the same training data set by randomly sampling with replacement the data. Sampling with replacement means that a specific row of data may appear more than once in the subsequent random sample. This means that each resultant model is trained against a slightly different sample of data. The resultant predictions from the multiple models are then all combined to create a single score.
Boosting

Boosting is another ensemble model-building method that was designed to help develop strong classification models from weak classifiers. Boosting methods focus on error (or misclassifications) that occur in prediction. After an initial model is built, the Boosting algorithm applies a series of weights to the data so that cases that were inaccurately predicted are given larger values and those that were accurately predicted smaller values. The classification algorithm is then re-applied to the data, but this time greater emphasis is given to correctly predicting the previously misclassified cases (i.e. those with the larger weights). The idea is that by repeatedly applying this approach, the algorithm attempts to hunt down the harder to classify cases.
Feature engineering
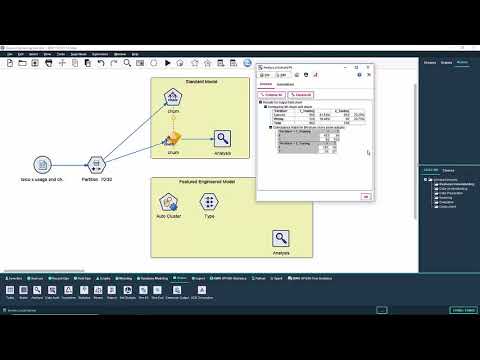
Feature Engineering is really just a fancy term for creating new data. Very often we can help an algorithm build better models by preparing the input data in a way that allows it to detect a clearer signal in the often noisy data. In machine learning variables are often referred to as ‘features’, so feature engineering refers to the transformation of variables or the creation of new ones.
Ensemble modelling
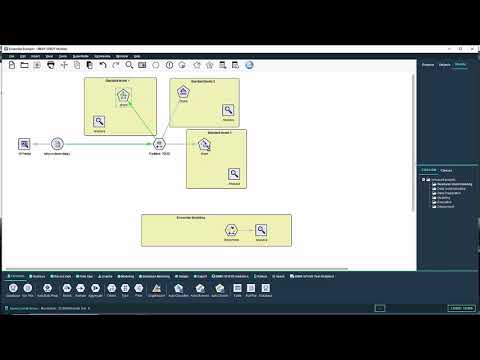
Ensemble modelling refers to the practice of combining the predictions of separate models on the old principle that “two heads are better than one”. Ensemble methods can be particularly effective when combining models that have been created using completely different algorithms. As each algorithm has its own unique set of strengths and weaknesses, it’s not surprising that there may be certain data rows that algorithm A is better at classifying than Algorithm B and vice versa. By combining the resultant models to create a single ensemble model, we often find that the overall accuracy of the ensemble method is better than any one individual contributing model.
Meta modelling
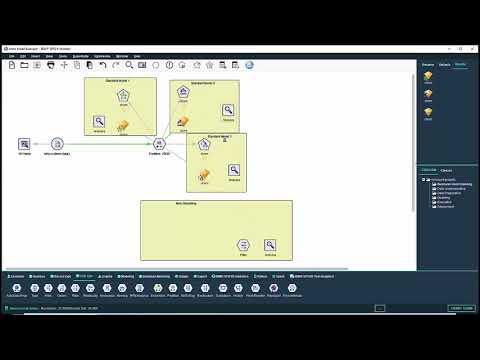
The idea of meta modelling is to build a predictive model using the predictions or scores generated by another model. By adding the predictive scores generated by an initial modelling algorithm to an existing pool of predictor fields, a second algorithm can then exploit these scores in to build a final more accurate model.
Split models
Split models or split population modelling is another technique that allows the user to build multiple models which can then be combined to create a single prediction. The idea with split modelling is that if the data represent different populations or contain separate groups that behave in very different ways, assuming that a single model can explain all the inherent variability across these distinct populations might be unreasonable. In which case, why not build separate local models for these key segments in the data and aggregate the resultant scores with the aim of increasing overall accuracy.