This post describes how to use Python scripts to create and modify Modeler supernodes, and control the execution of the nodes within the supernode. If you’re after a basic overview of Python scripting in Modeler then this post may be of interest, and I’ve also written about how to write standalone Python scripts in Modeler here.
As streams get larger and more complex, many users take advantage of supernodes in order to keep the structure of the stream understandable and maintainable. For example, a stream may contain multiple nodes for computing a summary of recent transactions (e.g. number of transactions over the last 1, 2 and 3 months, average spend over the last 1, 2 and 3 months, average spend per transaction, etc.). Rather than having all the nodes at the top-level in the stream, they could be combined into a single supernode with a descriptive label such as “Transaction Summary”. Someone looking at the stream can see that a transaction summary is being generated without having to see the details of how it is being computed – unless they want to of course.
There are three types of super-node:
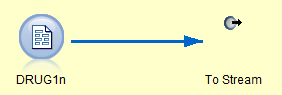
- Source supernode: contains one or more source nodes. If multiple source nodes are being used, the data sets must be combined using merge or append nodes so that only a single flow of data comes out of the node
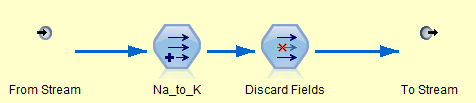
- Process supernode: contains multiple process nodes. Data comes into the supernode through a single connector and exits through another connector although the data flow may split and re-merge if necessary within the supernode.
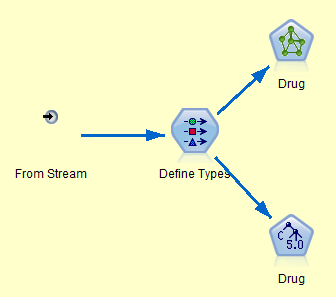
- Terminal supernode: contains multiple process or terminal nodes. If there are multiple terminal nodes within the supernode then executing the supernode will execute all of the nested terminal nodes
As can be seen from the screenshots above, the supernode includes special connectors which are created automatically depending on the type of supernode:
| Supernode Type | Input connector? | Output connector? |
| Source (“source_super”) | No | Yes |
| Process (“process_super”) | Yes | Yes |
| Terminal (“terminal_super”) | Yes | No |
Adding supernodes can affect how a script accesses and modifies the node settings and connections within the supernode. There are a couple of approaches:
- use a standard stream script to access the nodes within any super-nodes in the stream
- use a supernode script to modify and run nodes within the supernode
Using A Standard Stream Script
Supernodes contain an internal diagram which is a simpler version of a stream. This allows multiple nodes to be grouped together and hidden from the top level stream. The mechanisms for modifying connections and settings within the supernode diagram are the same as those for a normal stream. The only difference is how the supernode diagram is accessed.
A stream script can get access the stream that owns the script by using the stream() function in modeler.script module:
stream = modeler.script.stream()
To access a supernode diagram, the script needs to find or create the relevant supernode and then call the getChildDiagram() function:
diagram = my_supernode.getChildDiagram()
As noted previously, supernode diagrams include special connectors that are used to connect nodes within the supernode to the rest of the stream. These are accessed using the functions getInputConnector() and getOutputConnector(). For example, to create and connect a new filter node to the input connector:
filternode = diagram.create("filter", "My Filter")
To connect it to the output connector, use:
diagram.link(diagram.getInputConnector(), filternode)
To connect it to the output connector, use:
diagram.link(filternode, diagram.getOutputConnector())
Below is a script that creates simple stream made up from three supernodes (a source, a process and a terminal supernode). Each supernode contains a single child node so although it is not a sensible use of supernodes, it does provide the basic script code needed for constructing supernodes.
# Get easy access to the stream
stream = modeler.script.stream()
# Create the three supernodes and connect them
sourceSN = stream.createAt("source_super", "Source", 96, 96)
processSN = stream.createAt("process_super", "Process", 192, 96)
terminalSN = stream.createAt("terminal_super", "Terminal", 288, 96)
stream.linkPath([sourceSN, processSN, terminalSN])
# In the source supernode, create a var file node and connect it
# to the output connector
source_stream = sourceSN.getChildDiagram()
varfile = source_stream.createAt("variablefile", "File", 96, 96)
varfile.setPropertyValue("full_filename", "$CLEO/DEMOS/DRUG1n")
source_stream.link(varfile, source_stream.getOutputConnector())
# In the process supernode, create a type node and connect it
# to both the input and the output connectors
process_stream = processSN.getChildDiagram()
typenode = process_stream.createAt("type", "Type", 96, 96)
process_stream.link(process_stream.getInputConnector(), typenode)
process_stream.link(typenode, process_stream.getOutputConnector())
# In the terminal supernode, create a table output node and connect it
# to the input connector
terminal_stream = terminalSN.getChildDiagram()
tablenode = terminal_stream.createAt("table", "Table", 96, 96)
terminal_stream.link(terminal_stream.getInputConnector(), tablenode)
# Now run the terminal supernode. This in turn will run child table node
# and produce a table output
results = []
terminalSN.run(results)
Using a Supernode Script
A supernode script can be used to control execution of the child nodes without requiring that the whole stream is controlled by a script. This makes it simpler to share supernodes between streams without changing the way that the stream itself is executed. Note that only terminal supernodes support supernode scripts.
When a terminal supernode is executed, the terminal nodes within it are executed. However, when the supernode containing a script is executed, the supernode script is executed instead and it is assumed that this will execute one or more of the terminal nodes within it (although that is not a requirement). An example might be a supernode that contains a model builder node and an evaluation node, and the supernode script runs the evaluation automatically once the new model has been built.
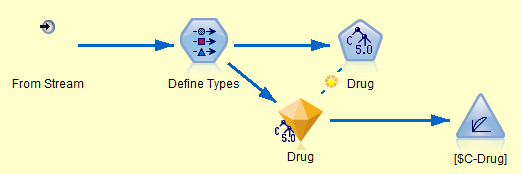
In the same way that a stream script needs to access the stream, a supernode script usually needs to be able to access the diagram within the supernode. Rather than use the modeler.script.stream() function which always returns the top-level stream, the script can use the diagram() function which returns the diagram in the supernode:
# Get easy access to supernode diagram
diagram = modeler.script.diagram()
# Find the C5.0 node and execute it
c50node = diagram.findByType("c50", None)
c50node.run([])
# Then execute the evaluation node
evaluationnode = diagram.findByType("evaluation", None)
evaluationnode.run([])
Note that the script doesn’t need to do anything explicit to capture the resulting model because the model builder is linked to an existing model applier via an update link (represented by the dotted line with a star shown in the supernode screen grab above). This means the model nugget will be updated with a new model automatically every time the model builder node is run.
Note also that although the supernode script does not “capture” the results of the execution itself, a calling stream script might. For example, suppose the stream is executed with the following stream script:
stream = modeler.script.stream() results = [] stream.runAll(results)
After execution, the results list will contain the both model and the evaluation output.