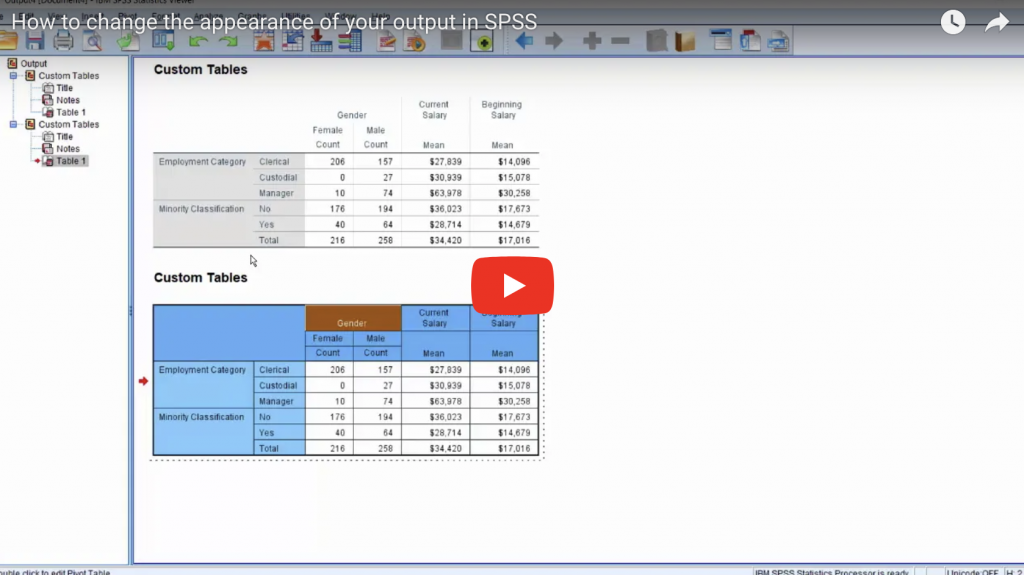
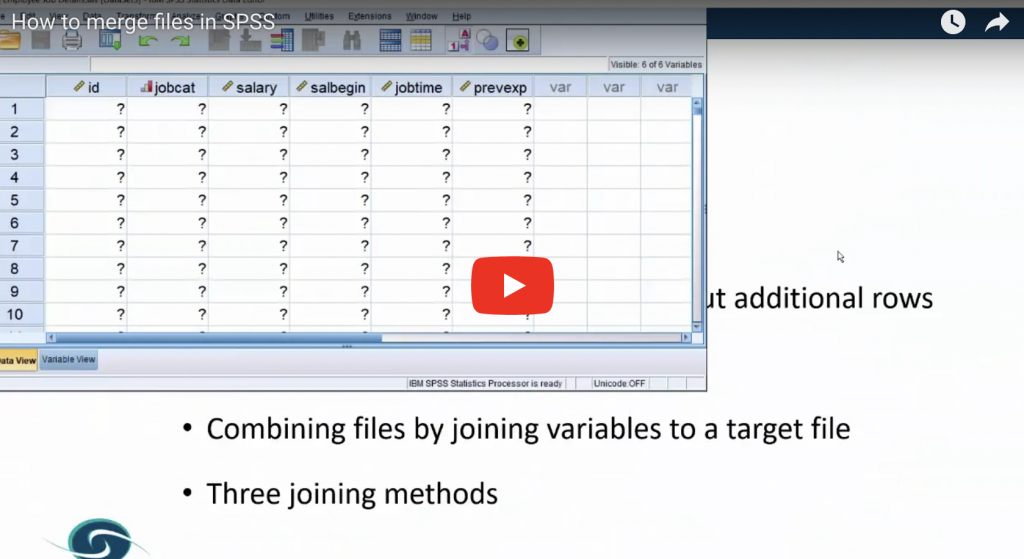
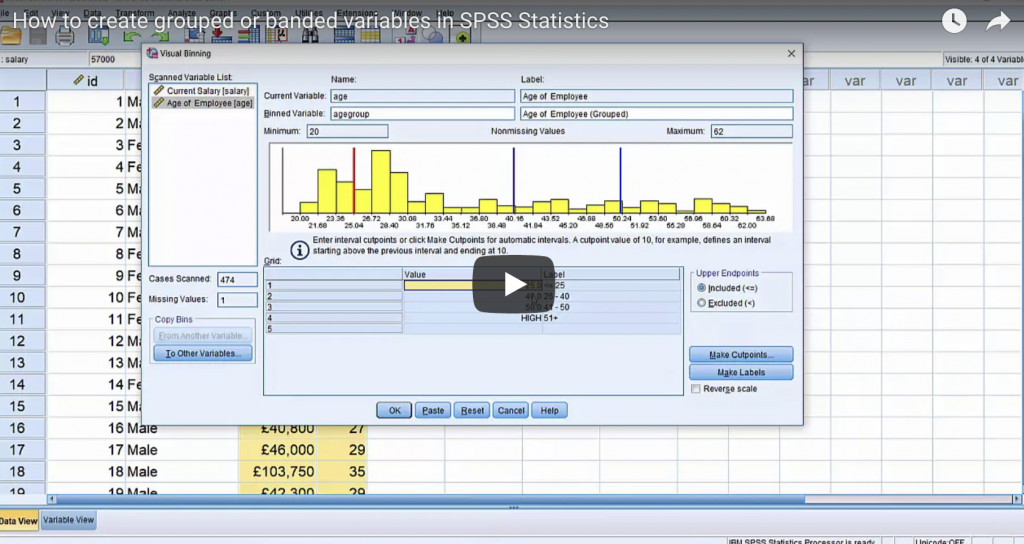
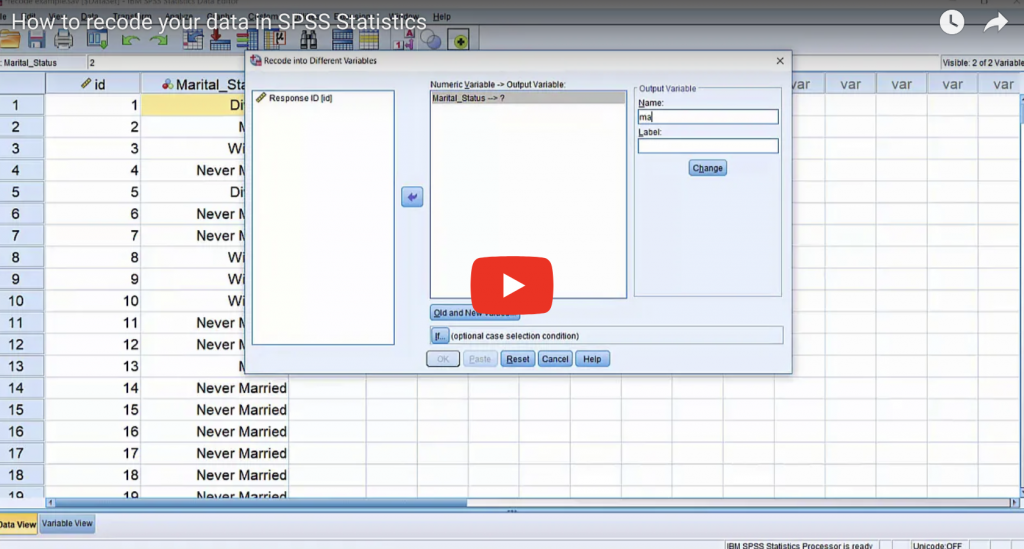
Why SPSS is a much better choice than Excel for data analytics
The volume and nature of the data that most organisations hold these days mean that the analytical possibilities are great. Organisations are constantly seeking ways to extract valuable insights from their data to gain a competitive edge, using advanced analytics to help them make data driven decisions. However, as with everything, it’s really important to …
Why SPSS is a much better choice than Excel for data analytics Read More »